Building a GPT-5 quality classifier at BERT cost: Our first live distilled classifier
Kalyan Dutia
We recently deployed our first classifier built through LLM distillation—a BERT model that matches GPT-5’s performance while running affordably across our 30,000 documents.
If you’re already familiar with our knowledge graph, feel free to skip ahead to ‘Finance flow: a high impact but challenging topic to classify’.
If you just want to see our tips and tricks from distilling a BERT model from a state-of-the-art LLM, jump to Distilling our first BERT classifier from an LLM.
Our knowledge graph and topic classifiers
We maintain a knowledge graph of climate-related topics that are valuable for our users to be able to find in documents. For each topic live in our tools, we build a classifier: a way of finding mentions of a topic in a passage of text. You see the results of these classifiers when you select the topic filters on our tools.
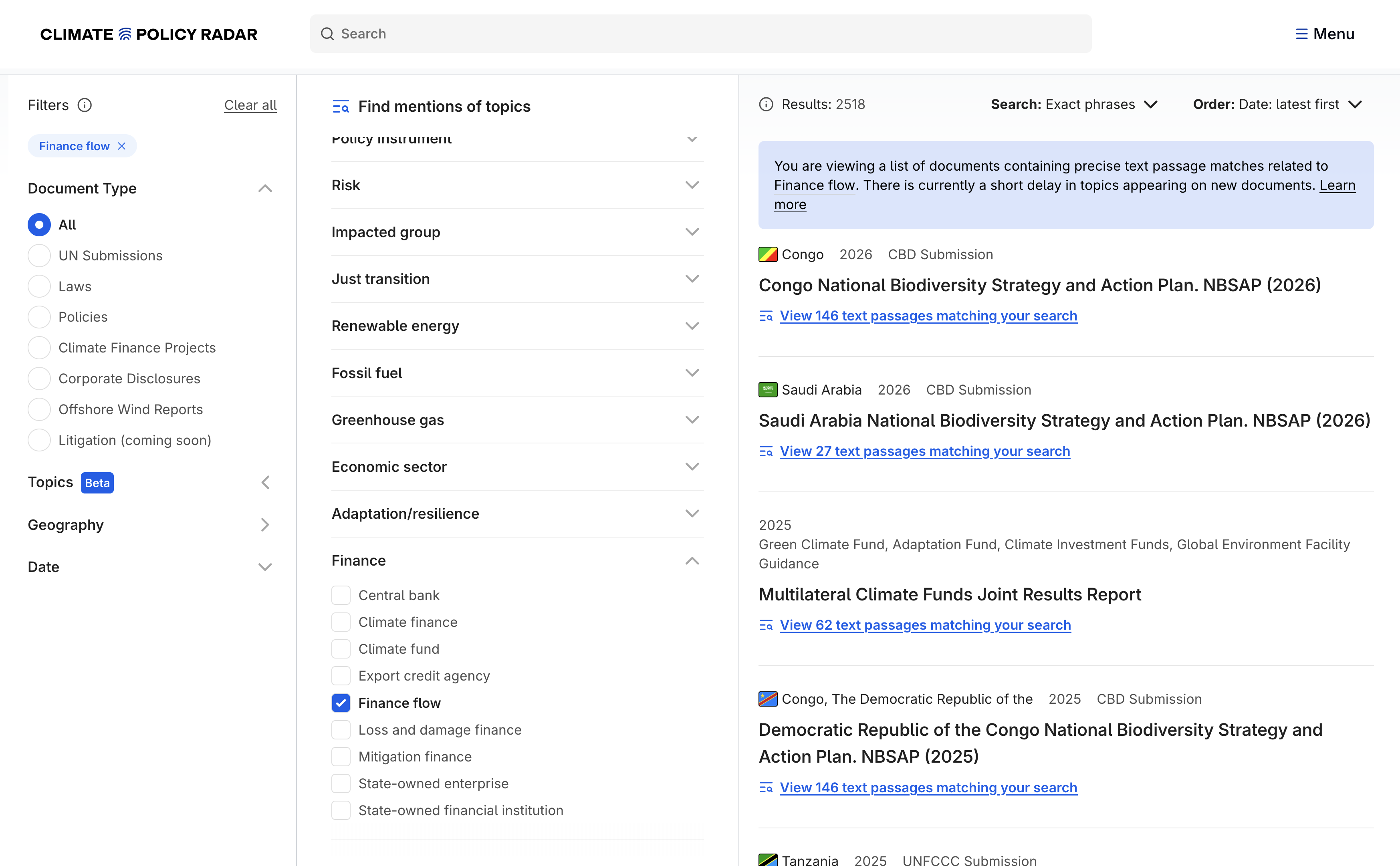
We currently have 1,561 topics in the knowledge graph, 100 of which are powered by their own single-class classifier. All but one of these classifiers so far work without any machine learning1 – they compile all of the labels (the “main” label, alternative labels and negative labels) from a concept in our concept store into a regex pattern, and we use that regex pattern as the ‘classifier’.
The one classifier that does use machine learning is our (policy) targets classifier. As the task of identifying whether a passage mentions a target is too complex to be handled by a regex pattern, we built this by finetuning a BERT model 2. This took us months and required thousands of expert-labelled passages and iteration on our methodology. For our small team, it’s infeasible to do this for each classifier we develop – so we needed another way to develop classifiers for harder concepts.
Finance flow: a high impact but challenging topic to classify
Identifying the transfer of economic value is a high impact topic for us, especially as we host a platform containing all of the project documents and policies from the Multilateral Climate Funds.
The definition from our concept store3 illustrates this:
A finance flow is an economic flow that reflects the creation, transformation, exchange, transfer, or extinction of economic value and involves changes in ownership of goods and/or financial assets, the provision of services, or the provision of labor and capital. Ideally, a financial flow describes four elements: the source (who is sending the financial asset, such as a bank or organisation); the financial instrument or mechanism (how it is being sent, such as a grant, loan or a subsidy); the use or destination (the purpose for which the asset will be used, which is often expressed as the recipient organisation or their sectoral categorisation); and the value (which can, but does not need to be, expressed in monetary terms directly). finance flow (Q1829) – Climate Policy Radar concept store
This is too challenging to be detected accurately by a set of regex rules or pretrained NER models. A classifier trained to detect monetary values would also include stocks – amounts held, rather than transferred. A regex statement like grant|loan|subsidy falls into the trap of financial metaphors in the English language – “I grant you permission…“.
Distilling our first BERT classifier from an LLM
Internally, we’ve been adapting active learning for LLM- and BERT-based classification – specifically addressing the poor probability calibration of these models. Our first learning when working on this concept was that we didn’t appear to need active learning – the GPT-5 generation of models perform well enough as zero- or few-shot classifiers for this concept, when coupled with some careful prompt tuning from domain-experts.
We followed a relatively simple process to build our distilled classifier, whilst building out the ability to track experiments in Weights & Biases as we went. As shown in the diagram, the process neatly split into enabling each team to focus on their area of expertise. Folks from our policy team (Anne and Siôn) applied their domain knowledge to iterate on annotation guidelines, produce a validation set, and create a classifier with an 85% F1 score. I then produced 5.5k training examples using this LLM, and finetuned a BERT model with those.
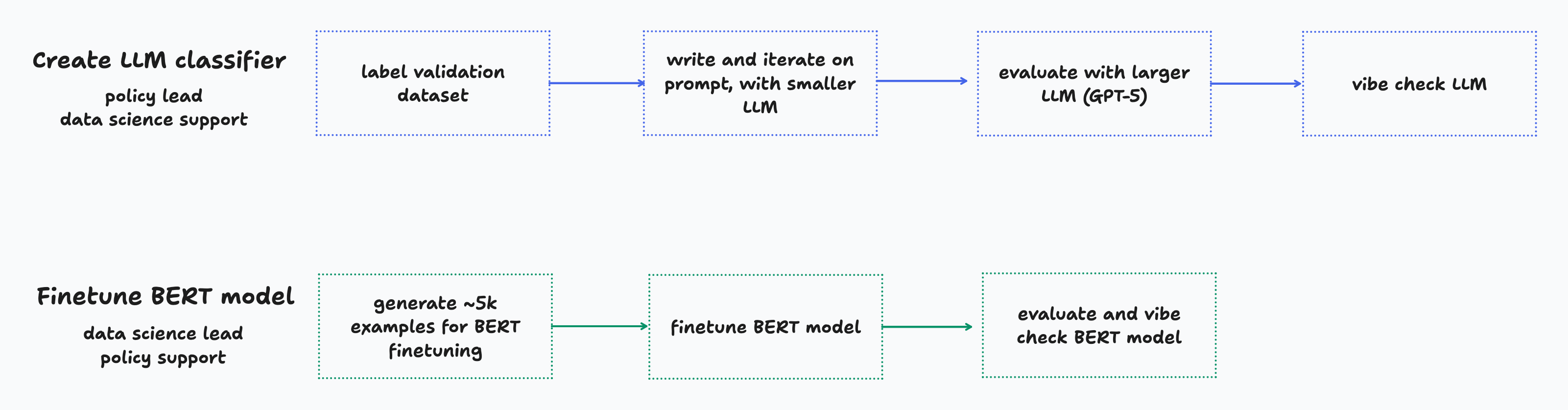
Despite being smaller by roughly four orders of magnitude smaller, the BERT model was competitive with GPT-5 in F1 score. After choosing a threshold which optimised BERT’s F1-score, we shifted the precision-recall tradeoff slightly in favour of greater precision4.
| Classifier Type | Precision | Recall | F1 | Support |
|---|---|---|---|---|
gpt-5-2025-08-07 |
0.906 | 0.793 | 0.846 | 446 |
climatebert/distilroberta-base-climate-f |
0.749 | 0.907 | 0.821 | 446 |
climatebert/distilroberta-base-climate-f - final model with optimised threshold |
0.788 | 0.872 | 0.828 | 446 |
Performance metrics of LLM and distilled BERT classifiers on the finance flow concept.
Lessons learned
We’d like to share some recommendations for those attempting similar work, based on some surprises we encountered along the way:```
- Iterate on a small model, test on a larger model from the same family. We found that prompts that worked well on say GPT-4o also worked well on GPT-5, so we saved money and energy iterating on the smaller model. We’ve carried this forward into experiments with Claude and Gemini since, and also found that classifier failure modes can vary quite wildly between model families.
- Prompting classifiers enables domain experts to create amazing models. Making state-of-the-art classifiers used to be a somewhat vibe-based art of steering the semantic content of a training dataset, and then finding ways to spot errors in the labels or annotation guidelines when the dataset reached a certain size. With the appropriate infrastructure and some early guidance, it seems like classifier development can be left in the hands of domain experts.
- ModernBERT-large shows no real improvement over climateBERT for this task. Unless you have the infrastructure to kick off parallel or scheduled training jobs, there’s still value in iterating with the much smaller distilRoBERTa-based climateBERT model.
Next steps
We’re currently building classifiers for our climate justice subconcepts. These are even harder, not least because of the intrinsic biases present in LLMs – and we’ll likely lean on the aforementioned active learning work to develop performant BERT models for these.
Footnotes
-
As a data science team, we always take the approach of building the simplest, lowest-cost system (or ‘smallest model’) that meets the performance requirement. More maintainable, steerable and cost-efficient keyword classifiers give us much more control over examining and correcting biases than finetuned BERT models would. ↩
-
Identifying Climate Targets in National Laws and Policies using Machine Learning (Juhasz et al., ICLR 2024) ↩
-
We store all of our concepts in a Wikibase instance we call our Concept Store. Our Head of Data Science Harrison wrote about why we need one on Climate Policy Radar’s blog. ↩
-
As we only show detected topics on our app via a filtering mechanism, precision dictates the experience of someone using those filters. An 80% precision means that 1 in 5 of the passages they see will be incorrect matches for the topic (false positives). We also want to show users as many of the mentions of the topic that are actually there as possible (high recall). Because of this, we think carefully about the trade-off between precision and recall for classifiers which have moveable thresholds. ↩